Behind the scenes
LiftOn is designed for lifting genes, transcripts and exons, with the capability to handle any feature or group of hierarchical features in a GFF or GTF file. It takes Liftoff [7] and miniprot [8] to improve protein-coding gene annotation. This section provides a more detailed explanation of how LiftOn algorithm works.
Deciding chromosomes and features for annotation lift-over
When transferring genomic annotations to different assemblies, it's important to be selective about which chromosomes to include. Take human as an example, for the mappings of the human annotation from GRCh38 to CHM13, we excluded all alternative scaffolds and patches from the GRCh38 genome and its annotation. Specifically, we excluded scaffolds ending in “_fix” and “_alt”, because they are duplicates or variants of sequences found on the primary chromosomes.
As for features, we suggest users map both 'gene' and 'pseudogene' features to prevent LiftOn from mistakenly identifying pseudogenes as genes. We also recommend excluding genes that overlap with rRNA genes in rDNA arrays [9] [10], which occur in hundreds of identical copies and vary widely among humans, creating problems for the alignment programs.
Matching miniprot & Liftoff genome annotation
Liftoff uses the 'gene – transcript – exon/CDS' or 'transcript – exon/CDS' hierarchy, while miniprot maps protein sequences to the genome, generating a 'mRNA-CDS/stop_codon' hierarchy in GFF or GTF format at the transcript level. To run the protein maximization algorithm, LiftOn must first match annotations between Liftoff and miniprot at the transcript level.
LiftOn uses gene loci lifted by Liftoff as anchors to identify corresponding miniprot annotations, guided by two key reasons:
(1) Liftoff incorporates an overlapping resolution algorithm to confirm whether lifted-over gene loci overlap with other annotations.
(2) miniprot lacks the ability to reconcile overlapping gene loci. Additionally, given that certain gene families comprise numerous genes, a significant drawback of miniprot is its tendency to map all proteins in these genes to every gene.
In most cases, miniprot identifies a single transcript per protein and aligns with Liftoff annotations. However, there are instances where miniprot detects multiple transcript copies for a protein, with more than one copy overlapping Liftoff annotations. To avoid gene fusion annotations, we first eliminate any transcripts spanning multiple loci. If multiple transcripts still persist, we select the one with the highest protein sequence identity score. Furthermore, if miniprot annotations do not overlap with those from Liftoff, we give precedence to Liftoff annotations.
Check out 'FAQ How do the annotations generated by Liftoff differ from those produced by Miniprot?' for the analysis of consensus and differences between Liftoff and miniprot annotations. Once a one-to-one mapping is established, LiftOn considers both Liftoff and miniprot CDS chains, initiating the protein maximization (PM) algorithm.
Protein-maximization algorithm
Step 1: Chaining algorithm
The chaining algorithm (Figure 66 A-E) starts by pairing up miniprot alignments with transcripts lifted over by Liftoff. After two transcripts are paired up, the protein sequences from the Liftoff and miniprot annotations are then aligned to the full-length reference protein, as illustrated in Figure 66 B. Subsequently, LiftOn maps the CDS boundaries from both the Liftoff and miniprot annotations onto the protein alignment (Figure 66 C).
The CDSs within the Liftoff and miniprot annotations are grouped from the 5’ to 3’ end direction. The CDSs group in Liftoff is represented as \(G_{L_i}\), while in miniprot, they are represented as \(G_{M_i}\). Here, \(i\) denotes the \(i^{th}\) group in that annotation.
The grouping process begins with the first CDS in each annotation and continues until reaching the endpoints of the downstream CDSs in Liftoff and miniprot, where the number of aligned amino acids from the reference protein is equal. This forms the first CDSs group in Liftoff, denoted as \(G_{L_1}\), and the first CDSs group in miniprot, denoted as \(G_{M_1}\). Subsequent groups start from the previous endpoint in both Liftoff and miniprot, extending until the number of aligned amino acids from the reference protein matches for both annotations again. These subsequent groups are represented as \(G_{L_2}\) and \(G_{M_2}\), respectively. The grouping process concludes upon reaching the last CDSs in both annotations.
Within each group, \(G_{L_i}\) or \(G_{M_i}\), we calculate the partial protein sequence identity and select the group with higher protein sequence identity score (Figure 66 D). In case of a tie, LiftOn prioritizes the Liftoff annotation, \(G_{L_i}\), to include UTRs in its output. The selected CDSs group, represented as \(G_{SEL_i}\), comprises the LiftOn CDS(s) within the LiftOn annotation. All \(G_{SEL_i}\) are then concatenated into the final LiftOn transcript (see Figure 66 E), which is an ordered sequence of CDSs originating from either Liftoff or miniprot, aiming to maximize protein similarity with the reference protein. This approach is particularly effective in addressing issues such as in-frame indels or mis-splicing that may arise from misalignments as illustrated by the \(L3\) alignment and the end of exon \(M6\), respectively, in Figure 66.
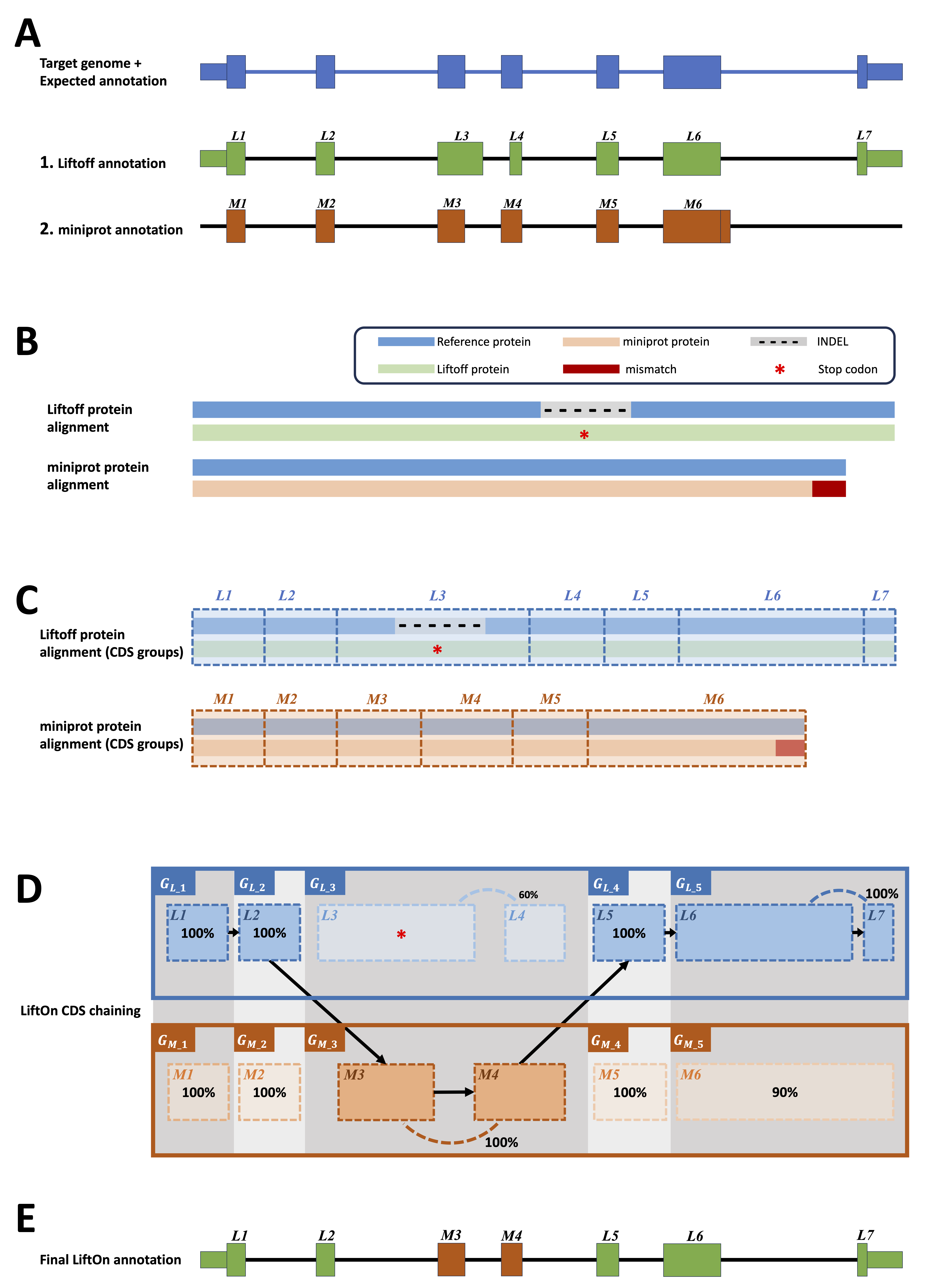
Figure 66 The ideogram depicts LiftOn's chaining algorithm. (A) Represents the expected lift-over of protein-coding transcript annotations from Liftoff (A.a) and miniprot (A.b). (B) Shows pairwise alignment results with variations. (C) Illustrates mapping CDS boundaries on protein-coding alignments. (D) Groups CDSs based on accumulated amino acids, iterates through each group, and chains those with higher protein sequence identity. In the example, CDSs \(L1\), \(L2\), \(M3\), \(M4\), \(L4\), \(L5\), \(L6\), and \(L7\) are chained, forming the new protein-coding transcript CDS list in the LiftOn annotation.
Step 2: Open reading frame search
Following the chaining algorithm, LiftOn performs an open-reading frame search algorithm on the protein-coding regions of the mapped transcripts that have mutations likely to be more deleterious, such as “frameshift”, “stop codon gain”, “stop codon loss”, and “start codon loss” mutations. The objective is to generate the longest valid protein sequences that align with the full-length reference proteins.
It searches the ORF translations of protein-coding transcripts and adjusts CDS boundaries to avoid early stop codons (Figure 67 A-B), choose better translation start sites (Figure 67 C, E, F), or extends proteins with stop codon loss (Figure 67 D), in order to produce the longest valid protein that match the reference protein.
Figure 67 Schematic diagram illustrating sequence mutations pre-LiftOn ORF search, altering gene annotation in translated and untranslated regions. (A) Frameshift mutation introduces early translation start. (B) Point mutations introduce early stop codons; LiftOn selects the longer part as proteins. (C) Point mutation introduces a premature stop codon. (D) Stop codon loss extends the protein. (E-F) Point mutation introduces a loss of the start site, and the LiftOn ORF search algorithm finds a downstream or upstream start site.
M: Methionine, the first amino acid; INDEL gap: DNA sequence insertion/deletion; UTR: Untranslated region; CDS: Coding sequence.
Mutation report
LiftOn identifies biological differences between reference and target genomes by aligning DNA and protein sequences. It classifies protein-coding transcripts as "identical" or provides detailed reports on mutations, including "synonymous", "non-synonymous", "in-frame insertion", "in-frame deletion", "frameshift", "start codon loss", "stop codon gain", and "stop codon loss".
Reference
- 1
Nuala A O'Leary, Mathew W Wright, J Rodney Brister, Stacy Ciufo, Diana Haddad, Rich McVeigh, Bhanu Rajput, Barbara Robbertse, Brian Smith-White, Danso Ako-Adjei, and others. Reference sequence (refseq) database at ncbi: current status, taxonomic expansion, and functional annotation. Nucleic acids research, 44(D1):D733–D745, 2016.
- 2
Fergal J Martin, M Ridwan Amode, Alisha Aneja, Olanrewaju Austine-Orimoloye, Andrey G Azov, If Barnes, Arne Becker, Ruth Bennett, Andrew Berry, Jyothish Bhai, and others. Ensembl 2023. Nucleic acids research, 51(D1):D933–D941, 2023.
- 3
Ales Varabyou, Markus J Sommer, Beril Erdogdu, Ida Shinder, Ilia Minkin, Kuan-Hao Chao, Sukhwan Park, Jakob Heinz, Christopher Pockrandt, Alaina Shumate, and others. Chess 3: an improved, comprehensive catalog of human genes and transcripts based on large-scale expression data, phylogenetic analysis, and protein structure. Genome biology, 24(1):249, 2023.
- 4
Stephen F Altschul, Warren Gish, Webb Miller, Eugene W Myers, and David J Lipman. Basic local alignment search tool. Journal of molecular biology, 215(3):403–410, 1990.
- 5
Steven Henikoff and Jorja G Henikoff. Amino acid substitution matrices from protein blocks. Proceedings of the National Academy of Sciences, 89(22):10915–10919, 1992.
- 6
Heng Li. On the definition of sequence identity. 2018. URL: https://lh3.github.io/2018/11/25/on-the-definition-of-sequence-identity (visited on 2024-01-29).
- 7
Alaina Shumate and Steven L Salzberg. Liftoff: accurate mapping of gene annotations. Bioinformatics, 37(12):1639–1643, 2021.
- 8
Heng Li. Protein-to-genome alignment with miniprot. Bioinformatics, 39(1):btad014, 2023.
- 9
Saumya Agrawal and Austen RD Ganley. The conservation landscape of the human ribosomal rna gene repeats. PloS one, 13(12):e0207531, 2018.
- 10
Kuan-Hao Chao, Aleksey V Zimin, Mihaela Pertea, and Steven L Salzberg. The first gapless, reference-quality, fully annotated genome from a southern han chinese individual. G3: Genes, Genomes, Genetics, 13(3):jkac321, 2023.