FAQ ...
Q: How do the annotations generated by Liftoff differ from those produced by Miniprot?
To determine how many protein-coding genes miniprot can map that are missed by Liftoff, and to assess the degree of consensus between Liftoff and miniprot regarding the coordinates of protein-coding gene loci, we investigated the results obtained by mapping the RefSeq release 220 annotations from GRCh38.p14 to T2T-CHM13 v2.
The majority of cases are '1-to-1 mapping', which includes a total of 128,351 protein-coding transcripts. Additionally, 1,986 protein-coding transcript loci are categorized under 'one-to-many mapping', with miniprot identifying a total of 7,150 transcripts. There are also 355 protein-coding transcript loci that fall under 'Liftoff-miniprot disagreement' and 334 loci under 'Liftoff misses'.
In summary, Figure A below illustrates the alignment of 130,337 (128,351 + 1,986) protein-coding transcripts with Liftoff to miniprot 1-to-1 mapping. Conversely, Figure B depicts 5,925 protein-coding transcript loci identified by miniprot as extra copies exclusive to miniprot and not overlapping with Liftoff loci."
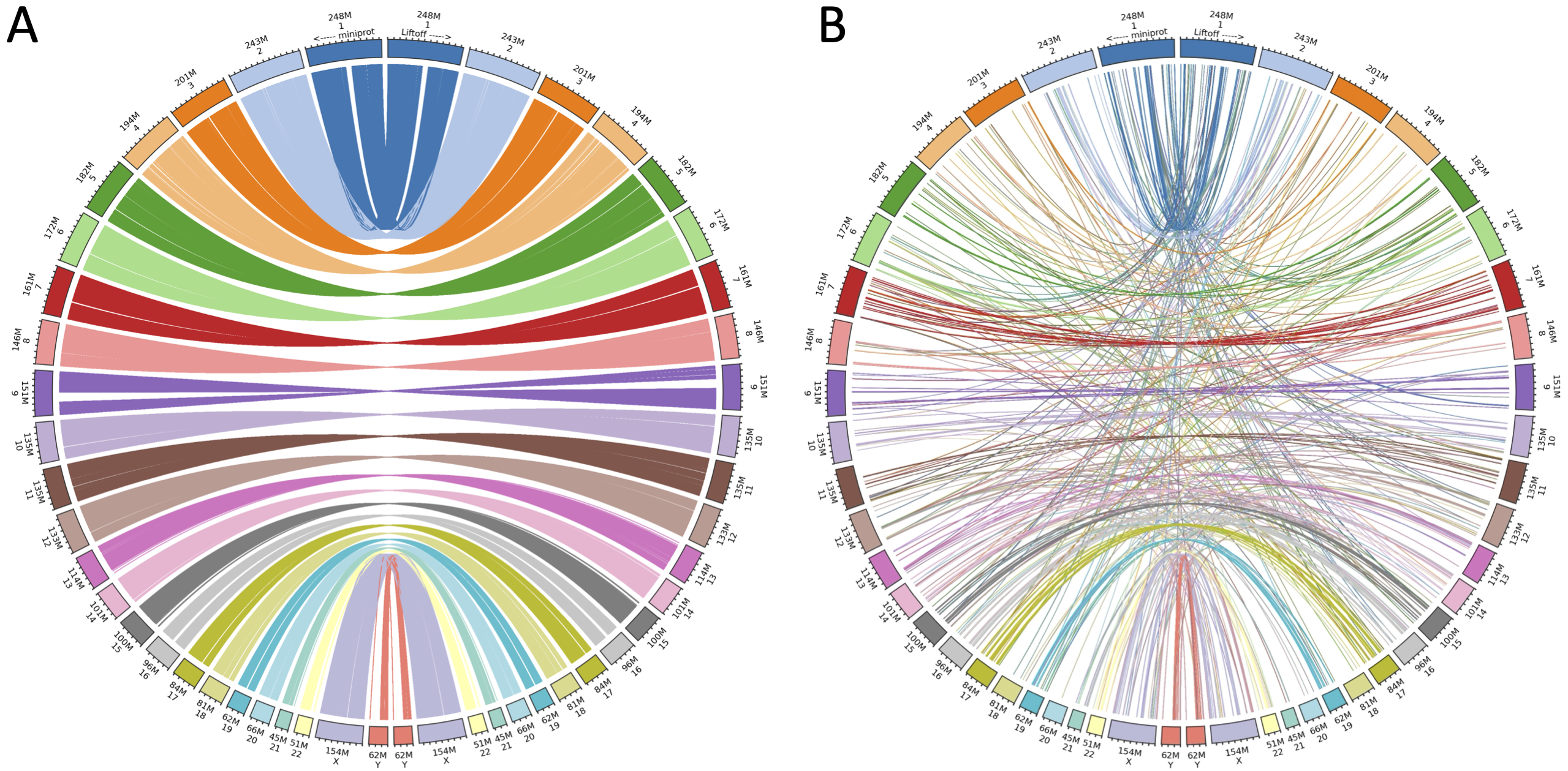
Q: How much does LiftOn improve over Liftoff and miniprot?
Here is one example of improvement over human annotation lift-over from GRCh38 to T2T-CHM13.
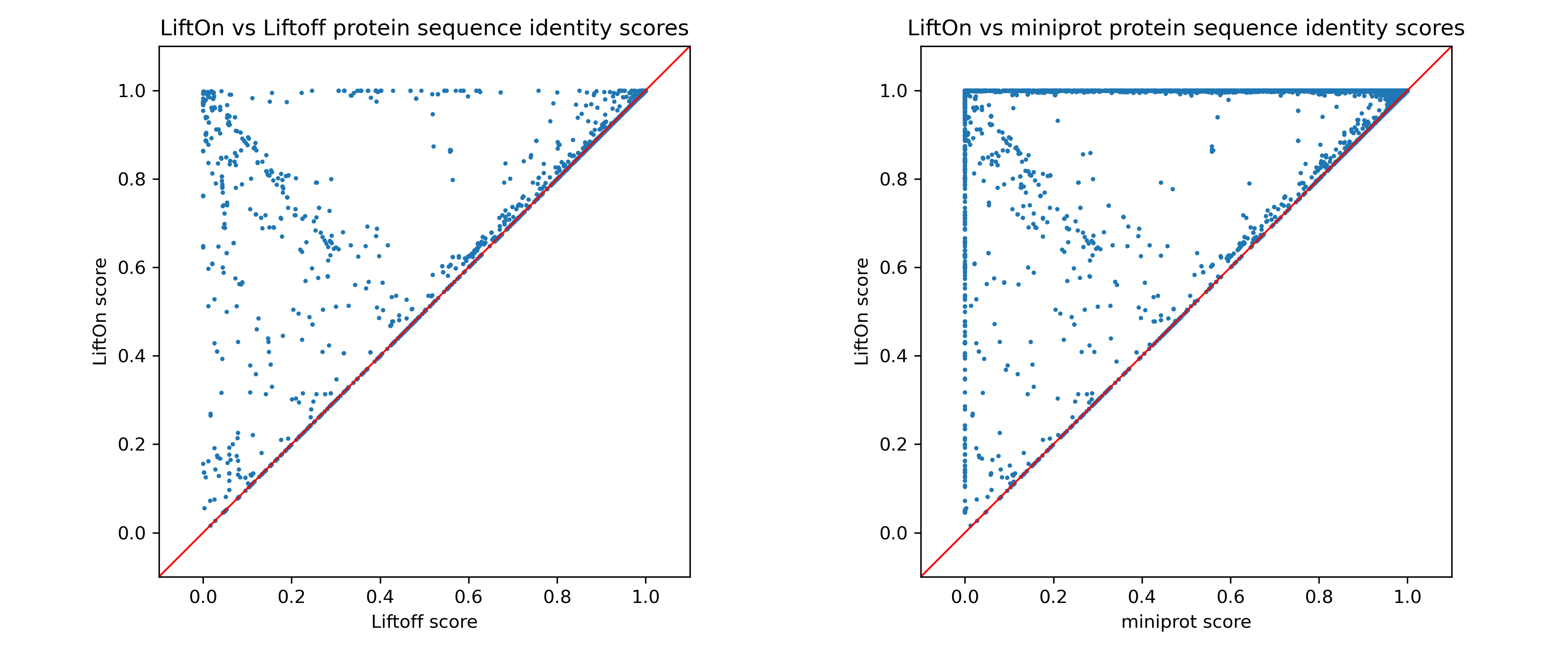
Each dot represents a protein-coding transcript. If it is above the x=y line, it indicates that the LiftOn annotation possesses a higher protein sequence identity score and corresponds to a longer protein that aligns with the proteins in the reference annotation.
In the LiftOn versus Liftoff comparison (Figure above, left), 2,075 transcripts exhibit higher protein sequence identity, with 460 achieving 100% identity. Similarly, the LiftOn versus miniprot comparison (Figure above, right) discloses better matches for 30,276 protein-coding transcripts, improving 22,616 to identical status relative to the reference.
In summary, LiftOn effectively corrects quite a few protein-coding transcripts during human lift-over. The improvement is even more significant when it comes to more distant species!
Check out the Same species lift-over section, Closely related species lift-over section, and Distantly related species lift-over section for more details.